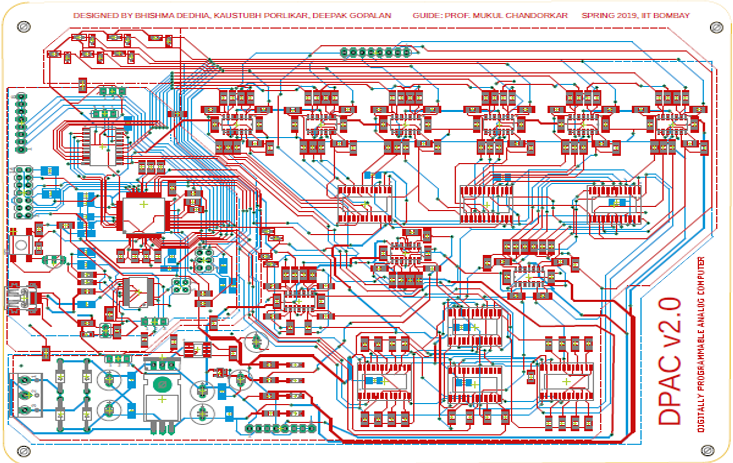
Digitally Programmable Analog Computer (DPAC)
In Spring 2019, Kaustubh Porlikar, Deepak Gopalan and I built a hybrid analog-digital computer for our Electronics Design Lab course at IIT Bombay. Many sleepless nights were involved.
The problem: Engineers often test controllers using simulated environments (hardware-in-the-loop). These simulations involve solving differential equations, which digital computers do iteratively—and slowly.
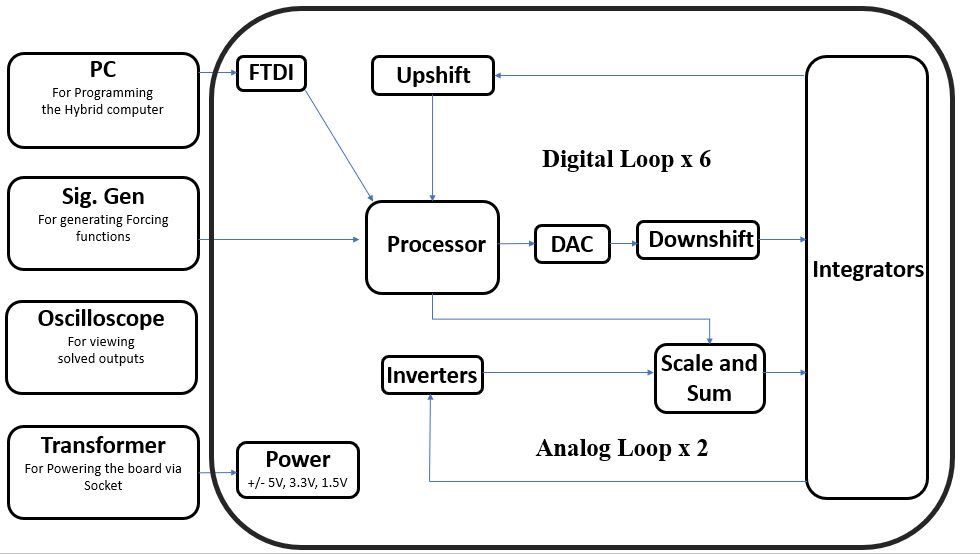
Our solution: Use analog circuits for the heavy lifting (integration via op-amps is instant), while a digital processor handles the tricky nonlinear parts. Best of both worlds.
DPAC v2.0 can solve systems up to 8th order, handling equations of the form:
- x' = Ax + bu + f(x,u)
- y = Cx + du + g(x,u)
where f and g are nonlinear functions.
The board is self-contained with onboard power management and can be programmed via its microcontroller. We also built DPAC β2.0, a smaller 2-variable version with programmable switches that let it adapt to different frequency ranges on the fly.
Full technical report here. Thanks to Prof. Mukul Chandorkar for encouraging this madness.