Hacks
Every once in a while my mind comes up with nutty proposals that become an itch I need to scratch. Unadulterated tinkering in a caffeine driven frenzy has occasionally yielded neat and useful hacks:
Digitally Programmable Analog Computer (DPAC)
Cometh the 6th semester in the life of an EE undergrad at IIT-Bombay, cometh the bountiful blessings of the Electronics Design Lab (EDL). The aim of the lab was to design and build a working prototype of any hardware system as long as it was useful. In the spring of 2019, three undergrads (Kaustubh Porlikar, Deepak Gopalan and yours truly) set out to conquer the Electronics Design Lab at IIT Bombay and sold their soul to the devil in the process, spending several nights hacking away on a computer design.
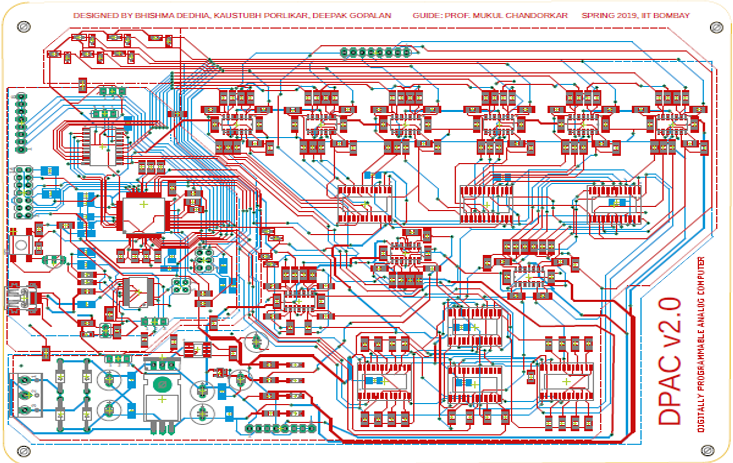
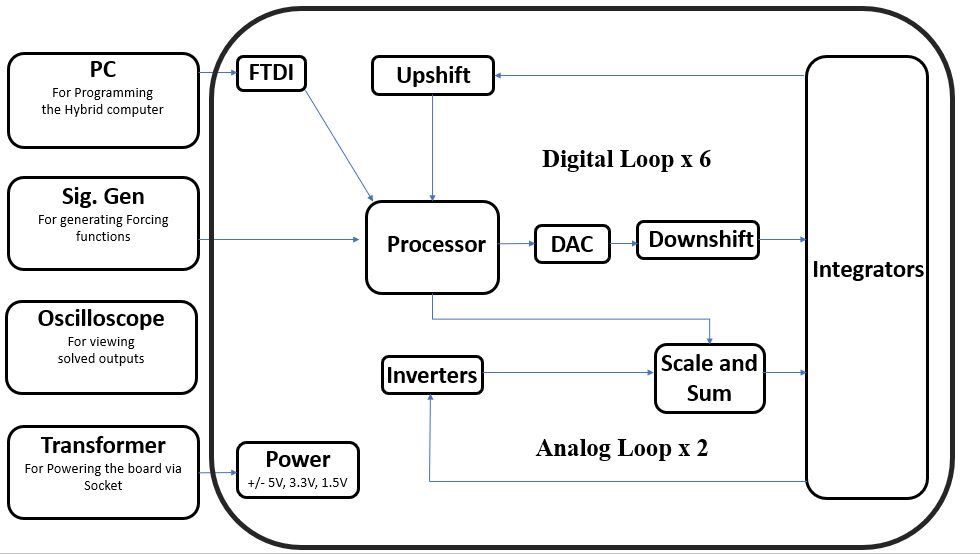
Hardware-in-the-loop simulations are very commonly used to test controller designs against realistic virtual stimuli produced by a computer. Often times, dynamical systems are in the form of coupled differential equations, and digital computers iteratively approximate solutions to such systems causing high latency. We built a hybrid computer to combine the high speed of the analog comuters with the versatility and precision of digital computers.
DPAC v2.0 is capable of solving upto an 8th order system of non-linear differential equations. We included a processor in the loop, to perform all the non-linear computations. The integration step has been done in the analog domain via op-amps. DPAC is capable of solving non linear dynamical systems upto 8 variables of the form:
- x' = Ax + bu + f(x,u)
- y = Cx + du + g(x,u)
Here f and g represent a wide class of non-linear operations. DPAC is completely self-sufficient with an onboard power management circuit and digitally programmable through the onboard microcontroller. In the process, we also designed DPAC 𝜷2.0, a miniaturized version of DPAC v2.0 having the capability of programming switches and solving 2 variable non linear systems. The programmability of switches enable the DPAC to change its configuration on the go and hence it can support a large range of frequencies. This report presents a detailed explanation of the intuitions, layouts and extensive experiments for DPAC 𝜷2.0 and DPAC v2.0. Major props to Prof. Mukul Chandorkar for supporting and encouraging this madness.
Solving a 30 year old puzzle: Lower Bounds for Simple Policy Iteration
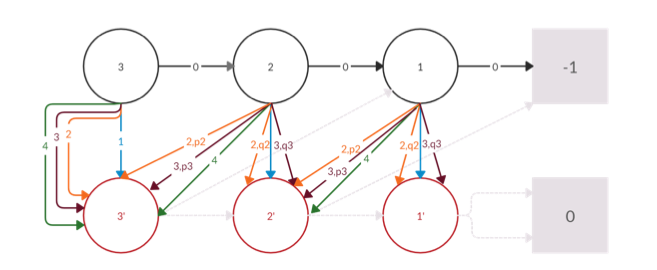
Markov Decision Processes (MDP) are used to abstract out the environment for a sequential decision making problem. In the most simple form, a MDP constitutes of a set of states, possible actions, discount factors and reward functions. Policy Iteration (PI) is an iterative algorithm that is used to obtain the optimal policy of a MDP, i.e. the policy that maximizes the expected return. PI consists of two fundamental steps performed sequentially in every iteration:
- Policy Evaluation: Given a policy, compute the value function of the policy.
- Policy Improvement: Given a value function, compute the optimal policy.
In Simple Policy Iteration (SPI), the policy of an arbitrary improvable state is switched to an arbitrary improving action. Specifically, the improvable state with the highest index is selected and its policy is switched to the improvable action with the highest index. Melekopoglou and Condon [1990] proved some lower bounds for simple policy iteration, for the special case of 2 actions. In late 2019, just for the thrills, a few of us spent some time scratching our heads to generalize this result to a multi-action case. In the process, we designed a new class of MDPs and proved non-trivial lower bounds on them, thus opening up new avenues for a 30 year old puzzle. A detailed report with the mathematical jargon can be found here